
With the understanding about partitions, the benefits of partitions and how to work with partitions from the article partitions-on-apache-hive, we are going to see a couple of potential problems that we may see with partitions, especially, with dynamic partitions. And, of course, how to address them using buckets. In this article, we'll discuss about:
- What are buckets?
- The differences between buckets and partitions.
- The benefits of using buckets in Hive.
- Creating bucketed tables in Hive and work with it.
Assume that we created a partition table named stocks_dynamic_partition which is partitioned by three columns: exchange name exch_name, year yr and symbol sym. Thus, we dynamically created hundreds of partitions on the table. Let's execute SHOW PARTITIONS stocks_dynamic_partition; to list all the partitions from the table.
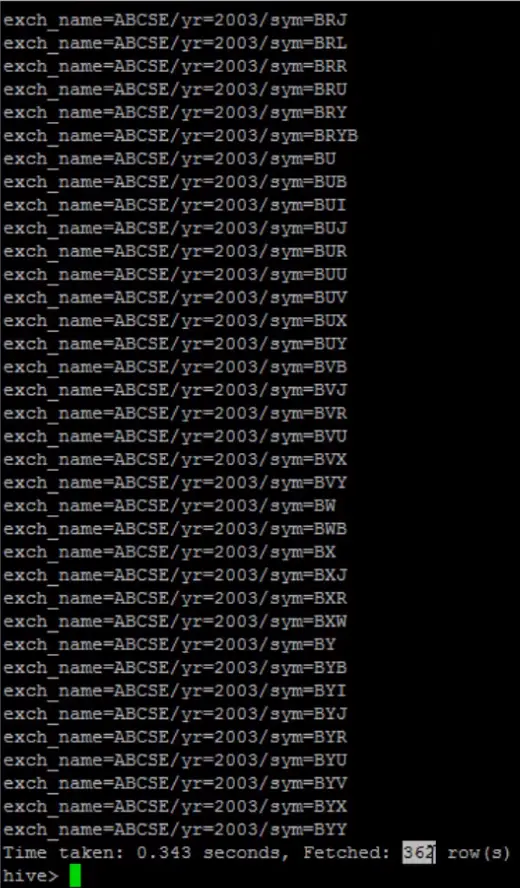
The screenshot shows that this table has about 362 partitions. We see a lot of partitions a lot of partitions for just 2003 and similarly for 2002 and similarly for 2001. Let's pick a symbol and go into the directory for a specific year.

As shown in the screenshot, there is a tiny file under the partition symbol BUB under year 2003.
There are two problems here:
- Problem 1: too many partitions. More symbol for a given year will end up with that many partitions. Meaning that for each year, based on the number of new symbols added to the exchange that year, the number of partitions can actually vary and it is not predictable.
- Problem 2: tiny files under the partitions. We know that Hadoop is not an ideal platform to deal with tiny files. We may argue that symbol is not the best column to partition a data byte but nevertheless, we could be facing a similar scenario in our job.
So, how do we address these two problems? The answer is buckets. Let's consider the following create table statement for creating a table stocks_bucket:
CREATE TABLE IF NOT EXISTS stocks_bucket (
exch STRING,
symbol STRING,
ymd STRING,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT)
PARTITIONED BY (exch_name STRING, yr STRING)
CLUSTERED BY (symbol) INTO 5 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
In this table, we are partitioning the table by exchange name and year, then we are saying CLUSTERED BY (symbol) INTO 5 BUCKETS which is that in first partition, the data is set by exchange name and year and once the data set is partitioned by year, the records for the year are stored into five buckets. In other words, five files using the symbol as our bucketing column. Each symbol is assigned to a bucket number using a hash function and all the records for that symbol will be stored into the assigned bucket. For example, if symbol XYZ is assigned bucket number 3, all records for XYZ will be stored in bucket number 3.
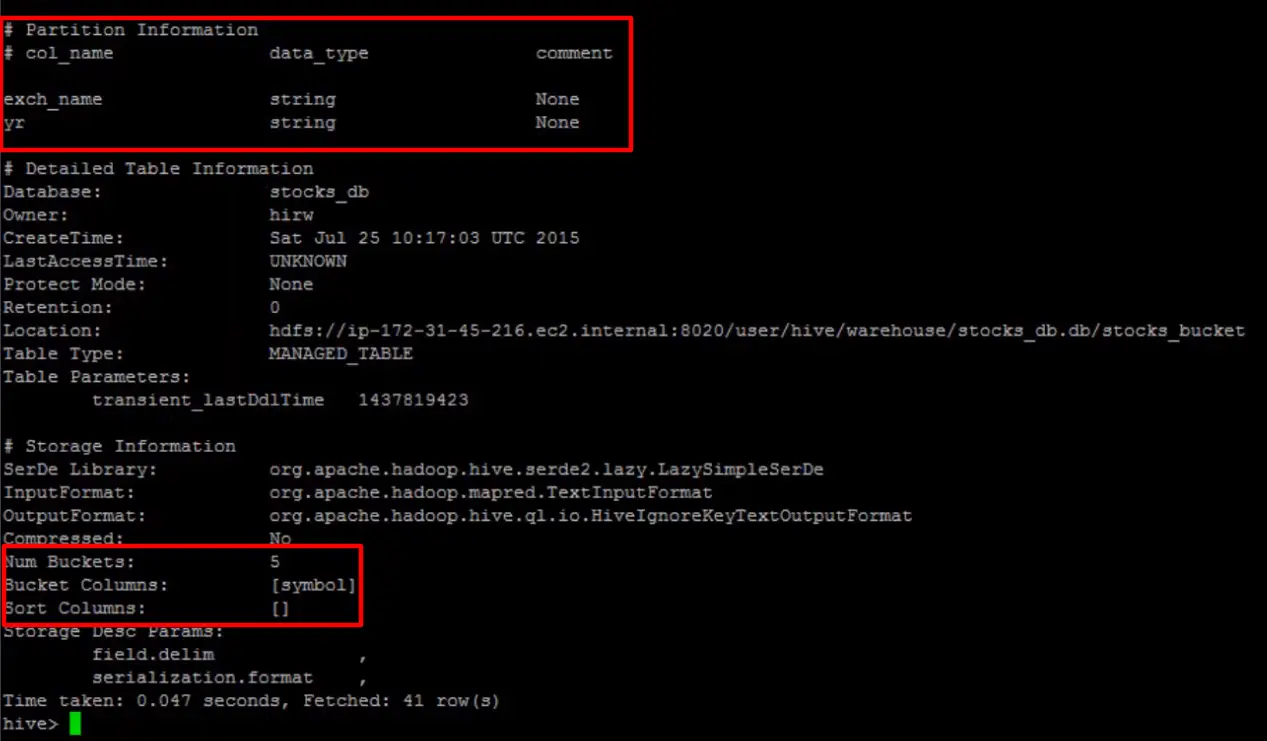
If we execute the describe command on the table as shown in the screenshot, and we can see the table is partitioned with two columns: exchange name and year, and the bucketed column symbol and the number of buckets is set to 5. Let's insert records into this table.
INSERT OVERWRITE TABLE stocks_bucket
PARTITION (exch_name='ABCSE', yr)
SELECT *, year(ymd)
FROM stocks WHERE year(ymd) IN ('2001', '2002', '2003') and symbol like 'B%';
The insert is just like any other insert, but make sure that hive.enforce.bucketing equals true (SET hive.enforce.bucketing = true;). Since this insert is going to create dynamic partitions as well, all the properties needed for dynamic partitions have to be set:
SET hive.exec.dynamic.partition=true;
SET hive.exec.max.dynamic.partitions=1000;
SET hive.exec.max.dynamic.partitions.pernode=500;
SET hive.enforce.bucketing = true;
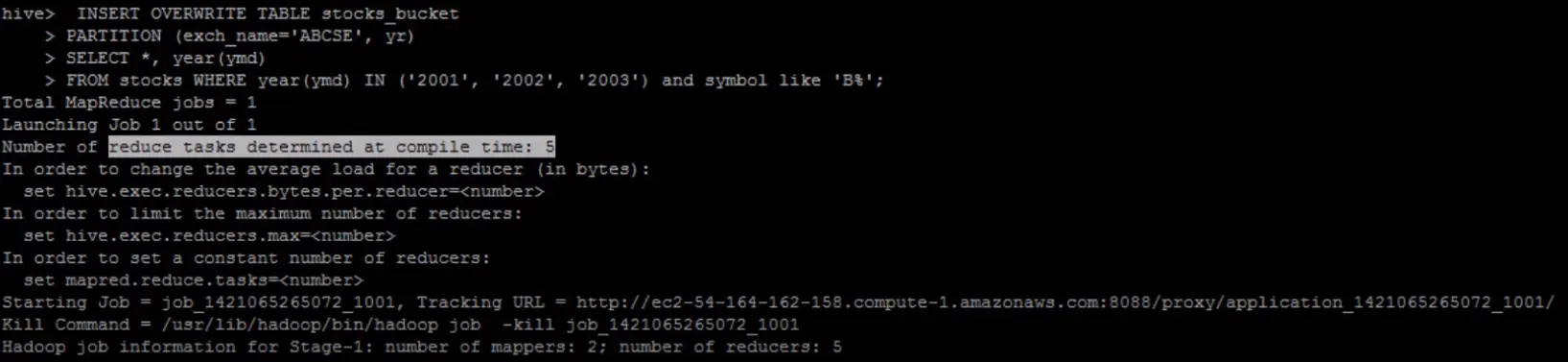
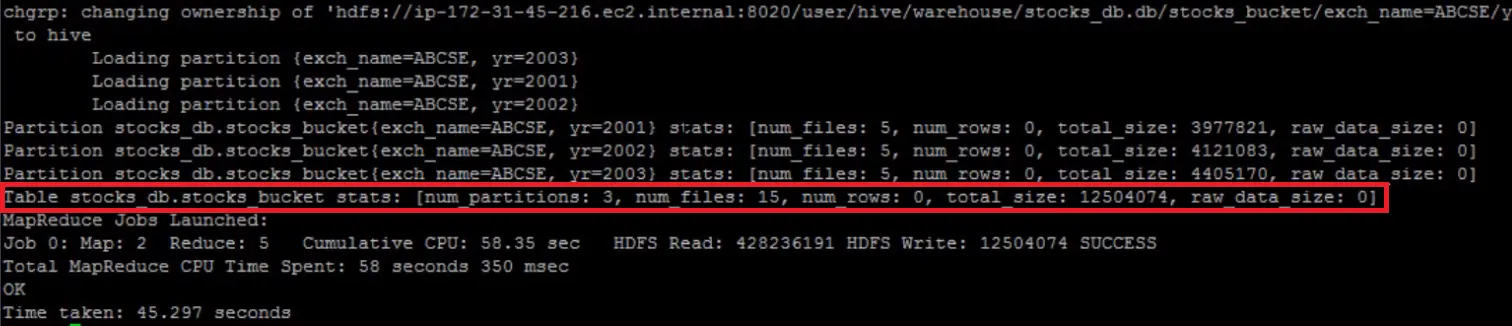
As shown in the screenshot, the number of reduced tasks determined at compile time equals 5 which equals to the number of buckets on this table which is also 5. When the insert is complete, three partitions got created for this table and under each partition, there are five buckets, so the number of files is 15 (five buckets under each partition). Let's look at the partition for year 2002.

As shown in the above screnshot, there are only five files or five buckets as opposed to too many tiny partitions. This is the benefit of buckets, we will get a constant number of buckets and also avoid tiny files. The second benefit of buckets is sampling. Sampling is beneficial when we don't want to query the entire data set and we would only like to analyze a random sample.
--Table sampling with out buckets
hive> SELECT *
FROM stocks TABLESAMPLE(BUCKET 3 OUT OF 5 ON symbol) s;
--Table sampling with buckets
hive> SELECT *
FROM stocks_bucket TABLESAMPLE(BUCKET 3 OUT OF 5 ON symbol) s;
In the first select, we're doing a table sample on a table stocks which is not bucketed and asking for bucket 3 out of 5 buckets based on the column symbol. Since this table is not bucketed, Hive has to randomly assign symbols into five buckets and rows which belong to the third bucket will be returned. The problem with this query is that: to return bucket number 3, the table sample needs to scan the entire table because the table is not bucketed and this is time intensive. On the other hand, the second select on the bucketized stocks_buckets table is efficient than the first one as the table we are sampling is bucketized and also the sampling is done on the bucketized column symbol. Hence, this query will be more efficient than the first one. The other benefits of buckets is its efficiency during map side joints. We'll look more detail into that in other article about optimizations.
In summary, we now understood what buckets are. We saw the difference between buckets and partitions. And we also know how to work with buckets. There are three benefits of buckets: (1) unlike partitions the number of buckets is constant and solves the tiny files issue, (2) buckets are very efficient when sampling tables and (3) finally the benefit of using bucket is during map site joints which we'll discuss in more detail later.
