
What is Big Data?
3 V's: Volume, Velocity and Variety
Volume
"Big" is a relative term. We put Shaq next to almost everyone, but especially gymnast Simone Biles, and he looks enormous. But if he stands with Yao Ming ... suddenly he doesn't look so big.

The same applies to data. What is considered "Big"? 10GB? 100GB? Or 100TB? There is no straight number that defines big data. There are two reasons why there is no straightforward answer to this question:
- What is considered as big today, in term of data size/volume, need to be considered as big a year from now. This is a moving target.
- It's all relative, as shown in Shaq's photos. What we consider to be big may not be the case for companies like Google and Facebook.
Hence, For these two reasons, it's very hard to put a number to define Big Data volume.
Let's say we are defining big data problems in terms of pure Volume alone. In our opinion, 100GB is not big data since we have a hard disk greater than 100GB. How about 1TB? It is still not because a well-defined traditional database can handle 1TB or even more without any issue. Then, 100TB? Some would claim that 100TB is a big data problem, and others might disagree. It is relative! So, 1000TB? Now, this is on a scale of Petabytes, and it is definitely Big Data.
Velocity
We have to understand that the volume of data is not the only factor in classifying our data be big data or not. Let's say we work at a start-up, and we recently launched a very successful email service where users can log in to send and receive emails. Our email service is so good and even better than Gmail. In three months, we have 100 thousand active users signed up to use our service.
Hypothetically, we are currently using a traditional database to store messages and their attachments, and also our current size of the database is 1TB. So, do we have a big data problem? The straightforward answer is NO because 1TB is not that big to classify as a big data problem. Another question: in this growth rate, will we have a big data problem in the near future? To answer this, we need to consider three factors.
The first one is volume. In 3 months, our start-up has 100 thousand active users, and our volume is 1TB. If we have a positive growth at the same rate, we will have 400 thousand active users at the end of the year, and our volume will be 4TB. What if we doubled or tripled our user base every three months, so the bottom line is that we should not just look at the volume when we think of Big Data. We should look at the rate at which our data grows. In other words, we should watch the velocity or speed of our data growth.
Velocity is the next important factor to consider; it tells us how fast our data is growing. If your data volume stays at 1TB for a year, all we need is a good database. If your growth rate is 1TB/week, then you have to think about a scalable Big Data solution. Most of the time, Volume and Velocity are all you need to decide whether you have a Big Data problem or not.
Variety
This is the next factor we need to consider; it adds one more dimension. Our data and traditional database are highly structured, which are rows and columns. Back to our hypothetical start-up email service, it receives data in various formats: texts for the actual messages, images, and videos as attachments. When we have data coming to our system in different forms and have to process or analyze the data in different formats, traditional database systems are sure to fit. When combined with high volume and velocity, you for sure have a big data problem.
Therefore, whenever we are asked whether it is a big data problem or not, please take the 3 V's: Volume, Velocity, and Variety into consideration. This happens to Big Data consultants all the time; they will be called in by clients about data storage that has performance issues and hope that a Big Data solution like Hadoop is going to solve their problem. Most of the time, their answer will fail in the volume and velocity tests, the volume will be in the higher gigabytes or lower gigabytes, and their growth rate has been relatively low for the past six months and in the foreseeable future. Hence, the volume does not qualify as big data, and their data growth rate will be very low. It fails the velocity test as well. What the client needs is to optimize the existing process and not a sophisticated Big Data solution.
Usecases
When we say Big Data, we are potentially talking about hundreds to thousands of Terabytes. Let's consider the following domains' use cases:
Science
Large Hadron Collider at SUN produces about 1TB of data every second, mostly sensor data from their equipment. Their volume is so big, that they don't even retain or store all the data they produce.
NASA gathers about 1.73 GB of data every hour about geolocation data from satellites, etc.
Goverment
NSA (National Security Agency) is known for its controversial data collection programs. An NSA data center in Utah can house 1 Yottabyte (1 trillion terabytes) of data in terms of Volume.
In March 2012, Obama's administration announced about 200 million dollars in Big Data initiatives. We can understand the significance behind Big Data and its analysis even though we cannot technically classify the next one under a government. And Obama's 2nd term election campaign used Big Data analytics which gave them a Competitive Edge to actually win the election.
Private
With the advent of social media like Facebook, Twitter, LinkedIn, etc., there is no scarcity of data: eBay is known to have a 40 Petabyte cluster and Facebook a 30 Petabyte cluster. These numbers are old now since the stats are a little old big data.
Data is not only produced and analyzed in social media companies but also retail space. It is most common in several major retail websites to capture click-stream data. For example, you shop at amazon.com. Amazon is not only capturing data when you click checkout but also every click on their website, which is tracked to bring a personalized shopping experience. When Amazon shows you recommendations, Big Data analytics is at work behind the scenes.
Big Data Challenges
Big Data comes with big problems:
-
Since data sets are huge, we need to find a way to store them as efficiently as possible. It is not just about efficiency in terms of **storage** space but also efficiency in storing the data set that is suitable for **computation**. The main purpose of storing data is to analyze them, right? How much time does it take to analyze and provide a solution to a problem using our big data? What's good in storing the data when you cannot analyze or process the data in a reasonable time? With big data set, computation with reasonable execution times is a challenge
-
Another problem when we deal with big data set is **data loss** due to corruption and data or due to hardware failure. You need to have a proper recovery strategy in place.
-
Finally, the **cost** and the most important challenge you're going to need a lot of storage space and a lot of computational power. Therefore, the solution that you plan to use should be cost-effective.
Traditional Solutions
RDBMS
Traditional RDBMS will have scalability issues when moving up in data volume in terms of Terabytes. We will be forced to demoralize and pre-aggregate the data for faster query execution time. As the data get bigger, we will be forced to make changes to the process in terms of changing the indexes, optimizing the queries, etc. Assuming that your database is running with enough hardware resources, when you see a performance issue, you still have to make changes to the query itself or the way in which your data is accessed. There is no working around it. You cannot add more hardware resources or more computer nodes and distribute the problem to bring the computation time down. In other words, the database is not horizontally scalable, i.e., you cannot add more resources or more computation nodes and hope the execution time or the performance will improve.
Databases are designed to process structured data. When our data does not have a proper structure, the database will struggle. Furthermore, a database is not a good choice when you have a variety of data which is data in several formats like texts, images, videos, etc.
A good enterprise-grade database solution can be quite expensive for a relatively low volume of data when you add hardware costs and platinum-grade storage costs. It's going to be quite expensive.
Grid Computing - A distributed computation solution
Grid computing is essentially many nodes operating on data parallelly and then doing faster computation. However, there are two challenges:
- Grid or high-performance computing is good for computing-intensive tasks with a relatively low volume of data but does not perform well when the data volume is huge.
- Grid computing requires a good experience with lower-level programming to implement and then it is not suitable for the mainstream.
Hadoop - A good solution
A good solution should, of course, handle a huge volume of data. It should provide efficient storage, which is the ability to store data efficiently. Data loss is unavoidable, so the proposed solution should implement a good recovery strategy. And the solution should be horizontally scalable as your data grows. Most importantly, it should be cost-effective. Finally, to minimize the learning curve, it should be easy for programmers, data analysts, and non-programmers to work with the framework or the system. This is exactly what Hadoop offers.
Is Hadoop a replacement for RDBMS?
NO!
| Hadoop | RDBMS |
|---|---|
| Hadoop has the volume in terms of petabytes | RDBMS works exceptionally well with volume in low terabytes |
| Hadoop can work with Dynamic Schema and supports files in many different formats | The schema is very strict and not so flexible and cannot handle multiple formats |
| Hadoop solution can scale horizontally | RDBMS's solution can scale vertically, meaning we can add more resources to the existing solution and to make any improvements to the process itself like tuning the queries and adding more indexes, etc. |
| Hadoop offers a cost-effective solution | It gets expensive very quickly when we increase the volume of data |
| Hadoop is a batch processing system, so we cannot expect a millisecond response time like an interactive system | RDBMS is an interactive and batch system |
| We can write the file or data once and then operate or analyze data multiple times | we can read and write multiple times |
The gaps between Hadoop and RDBMS are closing in. Hadoop offers a cost-effective solution to big data problems, but Hadoop is not the only solution that is available in the market now. NoSQL databases like HBase and Cassandra bring a great deal of value in analyzing a huge volume of data, and it is a great alternative for RDBMS. Now, when we mention a huge volume of data, we are talking about millions of columns and billions of rows.
Understanding Big Data Problem
Sample Big Data Problem
Imagine you work at one of the major exchanges like the New York Stock Exchange or NASDAQ. One morning someone from your Risk Department stops by your desk and asks you to calculate the maximum closing price of every stock symbol that is ever traded in the exchange since inception. Also, assume the size of the data set you are given is 1 TB, so your data set would look like the below image:

Each line in this data set is information about a stock for a given date. Immediately the business user who gave this problem asks you for an ETA on when he can expect the results. There is a lot to think about here, so you ask him to give you some time, and you start to work. What would be your next steps? You have two things to figure out: storage and computation.
Let's consider the storage first. Your workstation has only 20 GB of free space, but the size of the data set is 1 TB. Thus, you go to your storage team and ask them to copy the data set to a NAS (Network Attached Storage) server or even a SAN (Storage Area Network) server. Once the data set is copied, you ask them to give you the location of the data set. Because a NASA or san is connected to your network, any computer with access to the network can access the data provided if their permission to see the data. Thus, the data is stored, and you have access to the data.
Now, the next problem is computation. You're a Java programmer, so you wrote an optimized Java program to parse the data set and perform the computation. And you're now ready to execute the program against the data set. Unfortunately, you realize it's already noon, the business user who gave you this request stopped by for an ETA. Then, you start to think what is the ETA for this whole operation to complete, and you come up with the result set.
Execution Time
For the program to work on the data set, first, the data set needs to be copied from the storage to the working memory or Ram. How long does it take to copy a one-terabyte data set from storage? Let's take our traditional hard disk drive, which is the one that is connected to a laptop or workstation, etc. HDDs (Hard Disk Drive) have magnetic platters in which the data is stored. When you request to read data, the head in the hard disk first position itself on the platter and starts transferring the data from the platter to the head. The speed at which the data is transferred from the platter to the head is called the data access rate. Average data access rates in HDDs are usually about 122 MBs. So, to read 1 TB from an HDD, you need 2 hours and 22 minutes. That is for an HDD that is connected to your workstation.
When you transfer a file from a NAS server or from your SAN server, you should know the transfer rate of the hard disk drives in the NAS servers. For now, we will assume it is the same as the regular HDD, which is 122 MBs, and hence it would take 2 hours and 22 minutes. Next, what about the computation time? Since you have not executed the program yet at least once, you cannot say for sure. Additionally, your data comes from a storage server that is attached to the network, and you have to consider the network bandwidth also. With all that in mind, you give him an ETA of about three hours, but it could be easily over three hours since you're not sure about the computation time.
Data Access Rate + Program Computation Time (~60 min) + Network Bandwidth, etc. = (>3 hours)
Unsurprisingly, your business user is so shocked to hear three hours for an ETA he has the next question: can we get it sooner than three hours? Maybe in 30 minutes. You know there is no way you can execute the results in 30 minutes. Of course, the business cannot wait for three hours, especially in finance, for time is money.
How can we calculate the result in less than 30 minutes? The majority of the time you spend calculating the result set will be attributed to two tasks:
- Transferring the data from storage or hard disk drive is about two and a half hours and
- The computation time is the time to perform the actual calculation by your program (~ 60 minutes), it could be more, or it could be less.
What if we replace HDDs with SSDs (Solid State Drives)? SSDs are a very powerful alternative for HDD. SSD does not have magnetic platters, heads, or any moving components. And, it's based on flash memory, so it's extremely fast. By doing that, we can significantly reduce the time it would take to read the data from the storage. But here's the problem SSD comes with a price usually five to six times the price of your regular HDD. Although the price continues to go down, given the data volume that we are talking about with respect to Big Data, it is not a viable option. Therefore, for now, we are stuck with HDDs.
Let's consider how we can reduce the computation time. Hypothetically, the program will take 60 minutes to complete and is also already optimized for execution. We can divide the 1TB data set into 100 equal size chunks/blocks and have 100 computers/nodes to the computation parallelly. Theoretically, we cut the data access by the factor of 100 as well as the computation time. Hence, the data access time is reduced to less than 2 minutes (= 142 mins / 100), and the computation time is in less than 1 minute (= 60 mins / 100).
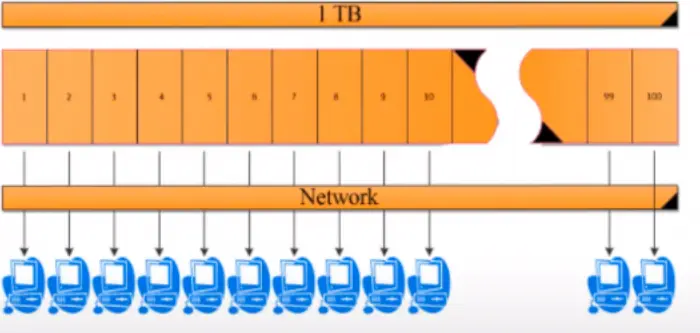
Furthermore, if you have more than one chunk of your data set stored in the same hard drive, you cannot get a true parallel read because there is only one head in your hard disk which does the actual read. For the sake of argument, assuming that we get a true parallel read, which means we have 100 nodes trying to read data at the same time. Assuming the data can be read parallelly, we will now have (100 x 122) MBs of data flowing through the network. Imagine what would happen when each one of your family members at home starts to stream their favorite TV show or movie at the same time using a single internet connection at your home? It would result in a very poor streaming experience with a lot of buffering such that no one in the family can enjoy their show. What we have essentially done is choked up your network; the download speed is requested by each one of the devices combinedly exceeded the download speed offered by the internet connection resulting in poor service. This is what will happen when 100 nodes try to transfer the data over the network at the same time.

To solve this, we can bring the data closer to the computation, i.e., store the data locally on each node's hard disk. Thus, you would store Block 1 of data in Node 1, block 2 of data in node 2, etc., as shown in the above image. Now we can achieve a true parallel read on all 100 nodes, and also, we have eliminated the network bandwidth issue. That's a significant improvement or design.
How can we protect our data from hard disk failure or data loss, data corruption, etc. ? For example, you have a photo of your loved ones, and you treasure that picture. In your mind, there is no way you can lose the picture; how would you protect it? You would keep copies of your picture in different places, maybe one on your personal laptop, one copy in Picasa, one copy on your external hard drive, etc. If your laptop crashes, you can still get that picture from Picasa or your external hard drive. From the idea, we copy each block of data to two more nodes. In other words, we can replicate the block in two more nodes. In total, we have three copies of each block.
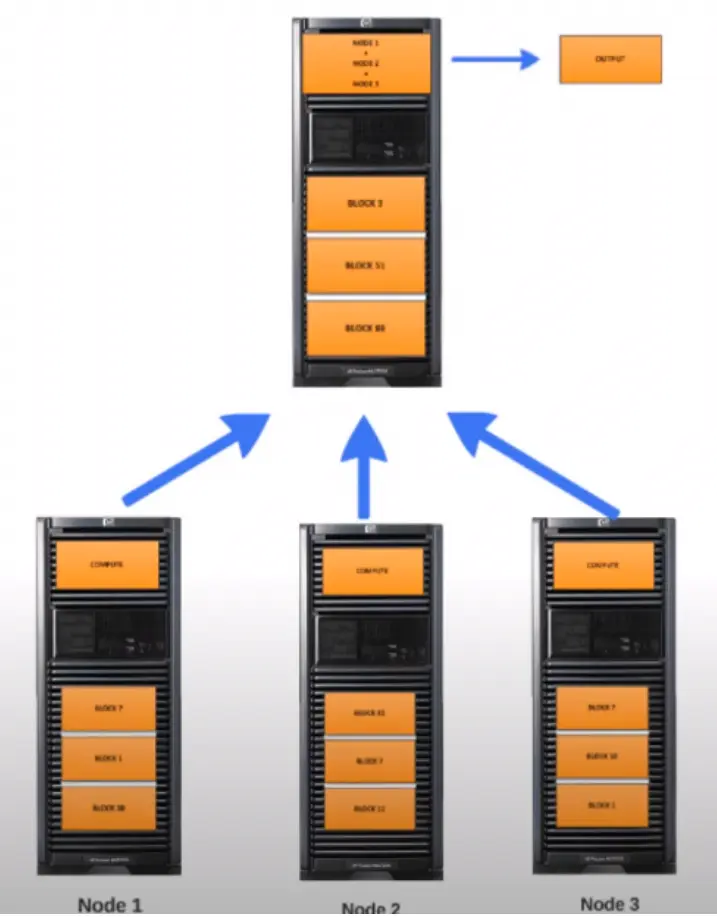
As shown in the above image, Node 1 has Block 1, 7, and 10. Node 2 has Blocked 7, 11, and 42. Node 3 has blocks 1, 7, and 10. If block one is unavailable in Node 2 due to a hard disk failure or corruption in the block, it can be easily fetched From node 3. This means that Node 1, 2, and 3 must have access to one another, and they should be connected to a network. But there are some challenges in implementing it; how does Node 1 know that Node 3 has Block 1? And who decides Block 7, for instance, should be stored in Node 1, 2, and 3. First of all, who will break the 1TB into 100 blocks?
That's just the storage part; computation brings other challenges. Node 1 can only compute the maximum close price from just Block 1. Similarly, Node 2 can only compute the maximum close price from Block 2. This brings up a problem because, for example, data for stock GE (a stock symbol) can be in Block 1 and can also be in Block 2 and could also be on block 82, for instance, right. Then, you have to consolidate the result from all the nodes together to compute the final result; who is going to coordinate all that? The solution we are proposing is distributed computing, and as we are seeing, there are several complexities involved in implementing the solution both at the storage layer and also at the computation layer.
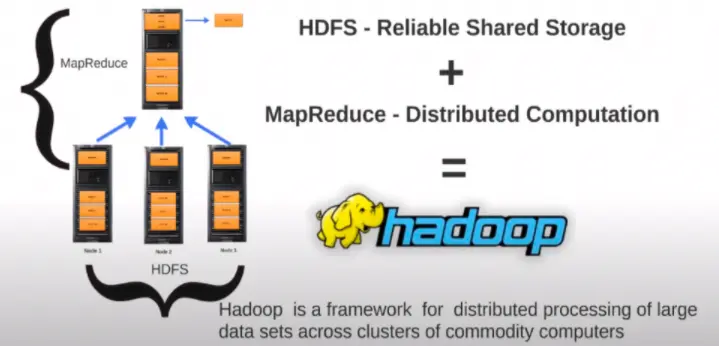
The answer to all these open questions and complexities is Hadoop. Hadoop offers a framework for distributed computing. Hadoop has two core components, HDFS and MapReduce. HDFS stands for Hadoop Distributed File System, and it takes care of all your storage-related complexities like splitting your data set into blocks, replicating each block to more than one node, and also keep track of which block is stored on which node, etc. MapReduce is a programming model, and Hadoop implements MapReduce, and it takes care of all the computational complexities. Therefore, Hadoop framework takes care of bringing all the intermediate results from every single node to offer a consolidated output.
What is Hadoop? Hadoop is a framework for distributed processing of large data sets across clusters of commodity computers The last two words in the definition are what makes Hadoop even more special, commodity computers, which means all the hundred nodes that we have in the cluster do not have to have any specialized hardware, i.e., their enterprise-grade server nodes with the processor, hard disk and RAM in each of them. There's nothing more special about that. But don't confuse commodity computers with cheap hardware. Commodity computers mean inexpensive hardware and not cheap hardware.
Now, you know what Hadoop is and how it can offer an efficient solution to your maximum close price problem against the 1TB data set. So, you can go back to the business and propose Hadoop to solve the problem and to achieve the execution time that your users are expecting. But if you propose a 100 node cluster to your business, expect to get some crazy looks; that's the beauty :)).
You don't need to have a 100 node cluster; we have seen successful Hadoop production environments from small 10 node cluster all the way to 100 to 1000 node cluster. You can simply even start with a 10 node cluster, and if you want to reduce the execution time even further, all you have to do is add more nodes to your cluster. That's simple. In other words, Hadoop will scale horizontally.
History of Hadoop
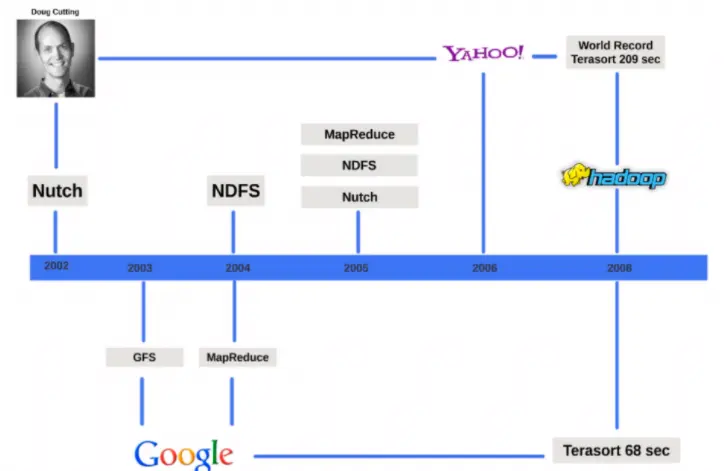
In 2002, an excellent and smart programmer named Doug Cutting was working on an open-source project named Nutch. The purpose of the nudge is to crawl the internet, collect web pages then rank and index them so that we can run searches against the indexed web pages. That is exactly what Google's search engine does. Google's proprietary crawlers and algorithms crawl through the internet, collect web page ranks and index them and run searches against them. Nutch is a very similar project to that idea, but it's open-source.
Soon, Doug Cutting realized that he was hitting scalability issues both in terms of storage and in terms of computation because he was collecting and trying to analyze a massive amount of data. While he was trying to solve the scalability issues, in 2003, Google published a paper about their proprietary homegrown file system named Google File System (GFS) and how it can be used to store massive amounts of data and offer redundancy and scalability at the same time. And in 2004, Doug created an open-source version of GFS and called it Nutch Distributed File System (NDFS). In 2004, Google published a paper on a programming model named MapReduce that addressed how Google achieved computational efficiency with Big Data. That is what Doug was looking for in terms of computation. And in 2005, Doug managed to run Nutch on top of NDFS and open-source implementation of MapReduce.
In Feb 2006, a sub-project named Hadoop was founded. Hadoop is the name of Doug's kids - A yellow stuffed elephant doll. He chose to use the name because it was easy to spell and meaningless. Around 2006, Yahoo started funding the efforts by Doug Cutting and building Hadoop and hired Doug. On Feb 19, 2008, Yahoo announced that they have the world's largest Hadoop production cluster. And in Jan 2008, Hadoop was made a top-level Apache project. In April 2008, Hadoop broke the world record and soldered a terabyte of data in 209 seconds. Later that year, in November, Google broke that same record and sorted a terabyte of data in just 68 seconds. Since its inception to date, Hadoop and its community have grown leaps and bounds and were soon embraced by several companies as a solution to analyzing Big Data.
Hadoop was truly given the ability to analyze volumes and volumes of data and helped unlock key valuable insights that would go unfound if it wasn't for this awesome technology. More importantly, Hadoop brought massive parallel distributed computing to the mainstream since it is open-source and can be implemented using commodity computers. And since it's open-source and can be implemented using commodity computers, Hadoop sets the bar very low in terms of cost of entry which enables even smaller companies to work with and analyze big data.
